
Back in the good ol’ days, before we talked about content curation as a next-generation web service, we lived in a curated web. Yes that’s right. Long before there were social networks, even before there were mainstream search engines, people found content online by navigating catalogs of carefully curated content, collections of hand-picked links, or hierarchies of meticulously organised pages. Back in the day, Yahoo! was the king of the curated web, providing millions of early web adopters with access to a carefully curated hierarchical catalog of pages and links. The catalog still survives today even though, by and large, we web users search for, rather than navigate to, the content we seek, but nonetheless in the pre-dawn of the modern web people located content by navigating through Yahoo!’s comprehensive catalog. Of course, then along came Google. And the rest, as they say, is history.
All that being said, history is wont to repeat itself and these days there is a strong move back to a curated web as one practical way to deal with the continued exponential growth of content and the eternal struggle that exists between search engines and SEOs to find or exploit the perfect ranking function. The simple truth is that these days there is a growing realisation that search engines are no longer top of the information discovery podium. Or at the very least they need to share this space with other tools and approaches to helping people find what they are looking for when they need it, and sometimes even before then realise they need it. Social networks, recommender systems, curation services all have a role to play in this.
Yuri Milner, the popular Russian Internet mega-investor who rose to fame through the significant positions he took in the likes of Facebook, Groupon, and Zynga, has called out curation as a key space for the future: “With the number of sources, and doubling of information every 18, 24 months. I think the next big thing is curation.” Indeed over the past few years we have seen the rise of some very significant content curation services from the image-focused Pinterest to news oriented Storify, and from tweet-powered Paper.li to the recently re-imagined Delicious, the grand-daddy of all social curation services. Most recently, Flipboard introduced curation as a centrepiece of it’s ground-breaking news-reader tablet-app by allowing users to create and share their own curated magazines based on the content they find in Flipboard. And for many content curation will be a major trend in 2014.
To date the focus of the curated web has been very much on providing curators with a set of tools to help them create, organise, manage and share curated collections of content. These approaches have helped to create novel curation experiences and gained real traction with users; for example, Pinterest’s visual content boards have attracted the attentions of millions of users, establishing Pinterest as a leading referrer of users to e-commerce sites (only after Google and Facebook) and spawning a multitude of clones.
But there remains some interesting opportunities when it comes to creating a more integrated discovery eco-system in which social networks, search engines, and curation services are capable of establishing a more symbiotic relationship to provide end-users with a more comprehensive, more reliable, more relevant, and more trustworthy content discovery solution. Early examples of this are starting to crop up, but all too often they reflect short-term local thinking that seeks to promote siloed content rather than a more open approach integrating curation, search and social. For example, Google’s self promotion of Google+ content has attracted the ire of many.
Here at HeyStaks we believe in a more democratic integration of curated and algorithmic search content. At it’s core HeyStaks is a curation service but a curation service with two rather unique differences.
First, it allows users to create curated collections of content, as do many others, but with the important distinction that they do so as a by-product of normal search. In other words, as you search, the queries that you use and the results that you select or otherwise act on, contribute to curated collections of content that you can securely share with communities of like-minded users, be they friends or co-workers or other interested parties. This provides a much more integrated way to capture interesting content by harnessing commonplace search activities and leveraging search engines that users already use on a daily basis.
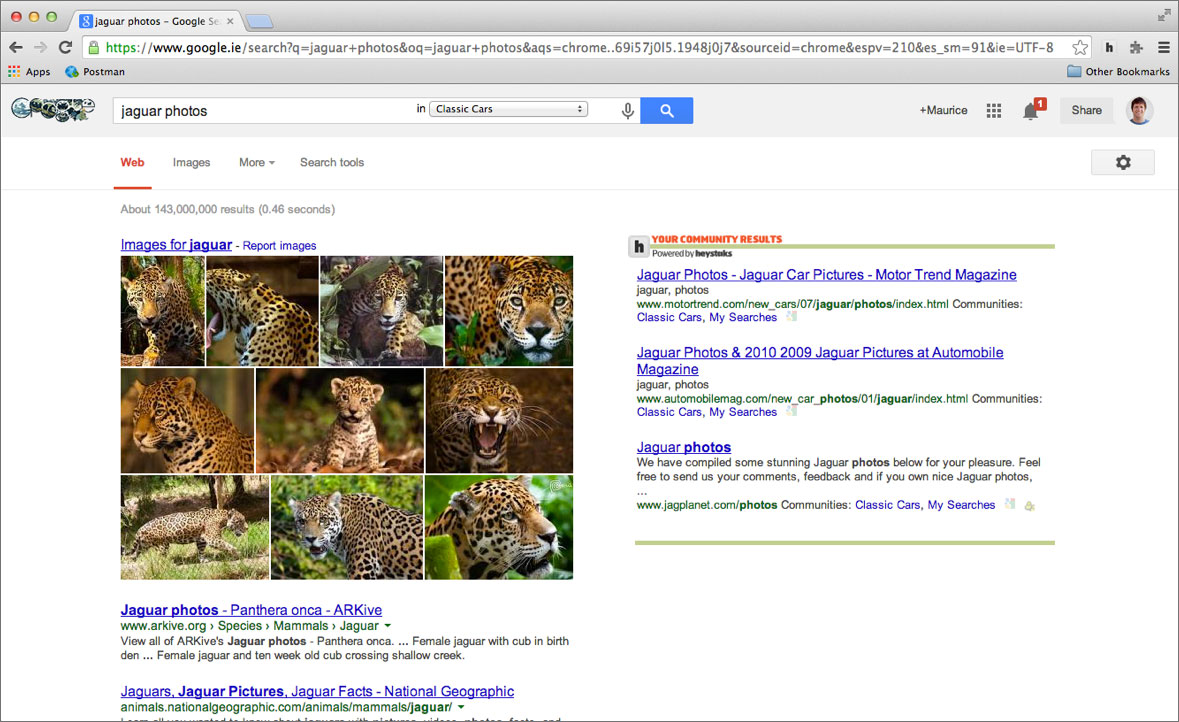
A screenshot of the HeyStaks Browser App in Chrome. The user has searched for the term ‘jaguar photos’, wanting to see pictures of classic cars. Google returns an animal focused result list [left column]. Because the user is a member of the ‘Classic cars’ community within HeyStaks, we deliver a list of high quality results focused on cars [right column], which have been curated by users with similar interests.
Second, access to curated content is also a by-product of search. As a HeyStaks users searchers, in addition to the organic (algorithmic) search content from their favourite search engine (e.g. Big, Google, Baidu, etc) they receive curated recommendations from communities of users with like-minded interests. Looking for photos of classic cars? Then you will enjoy recommendation from the most trusted “petrol heads” and classic car aficionados who have developed a reputation as the most trusted sources of restaurant recommendations. All this happens through your favourite search engine as you search as normal.
In this way HeyStaks can be viewed as providing a platform for curation as a natural by-product of search with the added advantage that curated recommendations can themselves enhance search relevance; for example, live user studies have demonstrated how these recommendations can garner significantly more selections from users compared to the click-through rate for organic results.
I think this will provide an interesting template for other types of curation services in the future. It is no longer unique to HeyStaks. For example, users of Evernote have a similar facility for some time, to surface notes as side-loaded recommendations in search engine result-lists. Here at HeyStaks we want to make this and similar initiatives as simple as possible so we have recently announced the HeyStaks API so that others can integrate our curation and recommendation platform directly into their services.
